Die Stadt Wien beheimatet eine Vielzahl an international bedeutenden Museen, die in den letzten zwanzig Jahren sukzessive ihre umfangreichen Sammlungen digitalisiert haben. Die Digitalisierungsaktivitäten haben durch die Pandemie an Tempo und Umfang zugenommen, wodurch einige Museen in Wien mittlerweile sehr große Datenbestände zugänglich gemacht haben, und dafür erfreulicherweise auch leistungsfähige Schnittstellen zur Verfügung stellen. Das Pilotprojekt „Linking Viennese Art through Artificial Intelligence” (LiviaAI) baut auf dieser neu geschaffenen Grundlage auf und adressiert dabei eine Schwierigkeit in der Nutzung von Online-Sammlungen: es gibt aktuell keine Möglichkeit alle Sammlungen über eine übergreifende Suche abzufragen.
Im LiviaAI-Pilotprojekt, gefördert vom Jubiläumsfonds der Stadt Wien für die Österreichische Akademie der Wissenschaften, werden daher Einsatzbereiche der Künstlichen Intelligenz erörtert, um Verbindungen und Ähnlichkeiten zwischen Museumsobjekten sammlungsübergreifend fassbar zu machen. Konkret baut das Projekt auf der Digitalisierungsgrundlage von drei Wiener Museen auf, dem Wien Museum, dem Museum für Angewandte Kunst, und dem Belvedere Museum Wien.
Das Projekt verfolgt drei Hauptziele:
- KI als Werkzeug für Digital Humanists und Museumskuratoren nutzbar zu machen, um die Verwendung von Klassifizierungssystemen und Vokabularen in Museumssammlungen zu untersuchen;
- Verbindungen zwischen den Online-Sammlungen unserer drei Museumspartner herzustellen, um damit Verknüpfungen zwischen einzelnen Objekten besser sichtbar zu machen;
- zu demonstrieren, wie KI neue Online-Ausstellungsformate unterstützen kann, die das zufällige Stöbern, das Erforschen von kontextuellen Zusammenhängen und die spielerische Auseinandersetzung mit dem kulturellen Erbe von Wien.
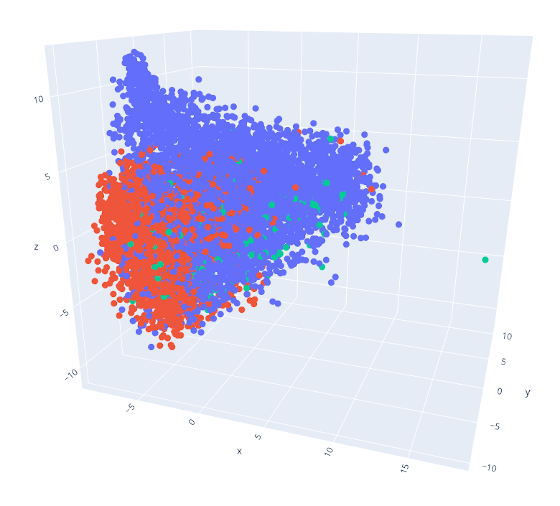
LiviaAI verknüpft Ansätze des maschinellen Lernens und der automatischen Sprachverarbeitung um schlussendlich ein KI-Modell zu erstellen, das die Ähnlichkeit zwischen Bildern von Kunstwerken auf Grundlage ihres visuellen Inhalts erkennt. Das Projekt sammelt dafür eine sehr große Menge an Beispielen von Bildern, die „ähnlich” bzw. „unterschiedlich” sind, so dass die KI daraus lernen kann. Um die Auswahl dieser Beispiele zu automatisieren, nutzt unser Prozess ein Verfahren aus der automatischen Sprachverarbeitung: wir haben in einem ersten Schritt die Metadaten von unseren Museumspartnern gesammelt - Bildbeschreibungen in Freitextfeldern, Schlüsselwörter, Künstler*innen usw. - und uns in ersten Analysen damit auseinandergesetzt, wie aus Metadaten auf „ähnliche” und „unterschiedliche” Bilder geschlossen werden kann. Insbesondere wurde dabei eine Methode namens „Sentence Embedding” genutzt. Diese Methode beruht auf einem multilingualen KI-Sprachmodell, das Sammlungsmetadaten zu Vektoren im Raum konvertiert, so dass ähnliche Metadaten im Raum nahe beieinander liegen (mehr dazu in unserem Blogpost). Im Austausch mit unseren Museumspartnern haben wir diese Methode adaptiert und testen sie aktuell im Vergleich zu Ergebnissen eines alternativen Verfahrens („Graph Embedding”), das lediglich die thematischen Schlagworte in den Metadaten berücksichtigt, aber keine Freitextinhalte wie Titel oder Beschreibungen.
Aus den Ergebnissen des Embedding erzeugen wir Dreiergruppen von Bildern (sog. „Triplets”, mit jeweils zwei ähnlichen Bildern und einem unterschiedlichen Gegenbeispiel) die dann die Grundlage für das KI-Training bilden werden. Derzeit untersuchen wir auch im Rahmen einer kleinen Crowdsourcing-Kampagne, inwiefern sich die automatisierte Triplet-Auswahl mit den Erwartungen der Benutzer*innen deckt, bzw. ob signifikante Qualitätsunterschiede zwischen Triplets bestehen, die mittels Sentence- bzw. Graph Embedding erzeugt wurden. Dazu sammeln wir über unseren Blog User-Bewertungen zu zufällige gewählten Triplets, die in weiterer Folge helfen sollen, das KI-Modell weiter zu verbessern.
Zentral in der Projektgestaltung ist der Input der Museumspartner. Insbesondere im Rahmen eines Workshops wurde deutlich, dass die Datenkurator*innen der einzelnen Museumssammlungen die besten Kenner*innen ihrer Datensammlungen sind und eine Rücksprache mit ihnen sehr hilfreich ist, um Daten und ihre Inhalte besser zu verstehen. Durch den Input der Datenkurator*innen konnten wir schon in der Frühphase des Projekts unseren Zugang zur Metadatenanalyse verfeinern, und die Datenqualität verbessern, indem wir gemeinsam Sichtweisen und Prioritäten diskutieren, sowie Unklarheiten und Fehler in der Schnittstellenbedienung ausräumen konnten.
Unser Fazit ist daher: Künstliche Intelligenz wird auch im Museumsbereich helfen mit der Informationsflut unserer aktuellen Zeit umzugehen und diese begreifbar zu machen. Aber ohne menschliche Akteure, die die Datengrundlage in harter und kleinteiliger Arbeit aufbereiten, zugänglich machen und erklären, sind kaum sinnvolle Ergebnisse möglich.
Weitere Informationen zum Projekt sind zu finden im Projektblog und auf der Homepage:

